ConvNeXt: A Transformer-Inspired CNN Architecture
The transformer architecture is one of the most important design innovations in the last ten years of deep learning development. The Facebook AI Research group did an extensive series of ablation studies to determine which aspects of the transformer architecture make it so powerful and adopted many of those designs to modify existing convolutional neural networks (specifically ResNet). In this blog post, we will look at those changes and their pivotal effect on traditional convolutional networks.
It’s important to note that in addition to changes that specifically emulated the transformer architecture, the team that designed ConvNeXt also used a novel combination of data augmentation techniques, regularization schemes, and stage compute ratios to boost performance beyond that of vision transformers.
“Patchify” Stem
In computer vision, the stem of a network typically refers to the first layer that input images will be passed through, and almost always involves downsampling the image and increasing feature map count (i.e. number of filter channels). In traditional ResNet architectures, the stem consists of a 7x7 convolution with a stride of 2, followed by max pooling.
It’s important to note that if kernel size is greater than stride (assuming no padding) in a convolution, the results will overlap. This means that as the kernel convolves over the input, the surrounding information is captured within each iteration of the kernel across the input, ensuring any relational data is captured.

In vision transformers and ConvNeXt, a more straightforward “patchify” stem is used instead. This is accomplished via a 4x4 convolution with a stride of 4, followed by layer normalization. By setting the kernel size and stride to the same value, we end up with non-overlapping convolutions. This means that as the kernel convolves over the input, no information is shared between them, producing unique patches. It’s worth noting, however, that each of these receptive fields are ultimately combined in the final layers of the network.
Interestingly, converting to a “patchify” stem resulted in a 1.1% increase in model performance.
Inverted Bottlenecks
In a vanilla residual block (ResNet block), the inputs pass through multiple convolutional layers, where the number of feature maps is downsampled upon entry and up-sampled upon exit. In parallel, a skip connection allows the original input to be added directly to the output of the final convolutional layer. This breakthrough innovation allowed neural networks to become much deeper while maintaining training stability, resulting in the ability to learn increasingly complex and abstract representations.

A design feature commonly found in transformer architectures is the Inverted Bottleneck block, a specialized type of residual block. The Inverted Bottleneck begins with a depth-wise separable convolution, which is the combination of two convolutional layers: a depthwise convolution followed by a 1x1 (pointwise) convolution where the feature map count is upsampled by a factor of 4. This is followed by another 1x1 convolution which downsamples the feature map count back to what it was upon entering the block, allowing for a skip connection to be made at the end.
ConvNeXt uses an Inverted Bottleneck block design that is essentially the same, with the addition of layer normalization and GeLU activation. This block design is extremely computationally efficient compared to a vanilla residual block.
Using an Inverted Bottleneck block inspired by transformers resulted in a 0.1% - 0.7% increase in model performance, dependent upon the training regime.
Fewer & Different Activation Functions
Activation functions are mathematical functions that allow for nonlinearity and are commonly applied to the output of a node or layer in neural networks. They are an essential component of any deep learning algorithm as they allow for complex relationships to be found within the input data. The most utilized activation function is the Rectified Linear Unit, commonly known as ReLU, and is employed in ResNet and the original transformer architecture published in 2017.
ReLU is heavily implemented in conventional ResNets and is typically inserted after every convolution. Conversely, transformers use relatively few activation functions at all since the self-attention mechanism serves as a form of nonlinearity. ConvNeXt mirrored transformers in this respect by utilizing only a single activation function per block placed between the 1x1 convolutions.

Some of the more modern, sophisticated transformer models, such as GPT-2 and BERT, utilize a different activation function known as the Gaussian Error Linear Unit, commonly referred to as GeLU. GeLU is a variant of ReLU, which has been shown to perform slightly better in certain architectures (such as transformers). Any instance of ReLU was replaced by GeLU.
Replacing ReLU with GeLU and decreasing the amount of activation functions resulted in a 0.7% increase in model performance.
Fewer & Different Normalization Layers
Transformers tend to have fewer normalization layers, as opposed to ResNet, which uses Batch Normalization after every convolution. ConvNeXt imitates transformers by removing most instances of normalization layers, only leaving them in place after the depthwise convolution in an inverted bottleneck block, in the classification head, and before the injection of a downsampling layer.
Additionally, transformers replace Batch Normalization with Layer Normalization, a simpler process that normalizes across the features of an individual input instead of the entire batch. ConvNeXt replaces any instance of Batch Normalization with Layer Normalization as well.
Replacing Batch Normalization with Layer Normalization and decreasing the amount of normalization layers resulted in a 0.1% increase in model performance.
Separate Downsampling Layers
ResNet employs downsampling at the beginning of the residual block by using a 3x3 convolution with a stride of 2. Notably, popular vision transformer architectures (such as the Swin Transformer) inject a separate downsampling layer between blocks rather than implementing downsampling within the blocks themselves. ConvNeXt replicated this as well, injecting a downsampling layer that starts with Layer Normalization, followed by a 2x2 convolution with a stride of 2 between each layer of blocks.
Introducing separate downsampling layers resulted in a 0.5% increase in model performance.
Conclusion
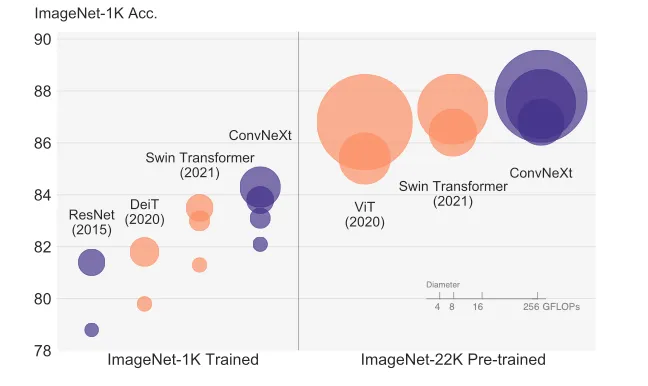
In the whitepaper, A ConvNet for the 2020s, researchers implemented transformer-inspired changes one by one on a ResNet-50, resulting in a new model architecture dubbed ConvNeXt. This new model was able to achieve an accuracy of 82.0% on the ImageNet classification task, outperforming the Swin Transformer. ConvNeXt can outperform vision transformers while retaining the straightforward, fully-convolutional architecture of ResNets for both training and testing, enabling simple deployment.
ConvNeXt is a high-performance computer vision architecture that can be applied to a wide array of applications. While there are many distinctive features not discussed in this post that make ConvNeXt so popular, these specific modifications inspired by transformers allowed ConvNeXt to outperform ResNet and existing vision transformers - all while using fewer parameters and requiring fewer computational resources.



